"Перемешивание" программ
На предыдущих этапах граф потока управления функции был значительно увеличен в размерах, затем в него было добавлено большое количество несущественного кода. И предикаты, добавленные в расширенный граф потока управления для моделирования исходного графа потока управления, и несущественный код используют множество переменных, не пересекающихся с основными переменными маскируемой функции. В результате функция может быть расслоена на существенную и несущественную часть, хотя это может быть и затруднено необходимостью проведения анализа указателей.
Чтобы затруднить отделение несущественной части замаскированной функции в неё добавляется большое количество искусственных зависимостей по данным между существенной и несущественной частью. Для этого в настоящее время используются булевские, теоретико-числовые и комбинаторные тождества, а также массивы и динамическе структуры данных.
Булевские тождества. Булевские тождества применяются для усложнения булевских выражений, которые определяют условные переходы. В отличие от других видов тождеств, булевские тождества произвольной сложности легко могут получаться автоматически. Рассмотрим в качестве примера основной метод получения булевских тождеств, реализованный в настоящее время.
Булевские тождества произвольной сложности могут быть получены из булевских тождеств относительно простой структуры при помощи набора эквивалентных преобразований. Пусть мы хотим составить булевское тождество с переменными v1, v2, ..., vk, среди которых есть как переменные исходной функции, так и несущественные переменные, внесённые при маскировке. Пусть e - выражение, подвергаемое усложнению. Тогда строится выражение

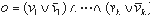
Такой метод получения булевских тождеств аналогичен методу получения непрозрачных предикатов, рассмотренному в работе [8], но в данном случае использование тождеств не приводит к появлению недостижимой дуги графа потока управления, которая достаточно легко может быть обнаружена.
Поэтому использование булевских тождеств в нашем случае обнаруживается значительно сложнее.
Комбинаторные тождества. Все рассматриваемые далее тождества, как комбинаторные, так и теоретико-числовые взяты, в основном, из [3]. Рассмотрим в качестве примера следующее биномиальное тождество
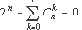
Тождество может использоваться следующим образом: в качестве n берётся несущественная переменная, принимающая целые значения в небольшом интервале (например, от 0 до 5). Генерируются инструкции, вычисляющие сумму биномиальных коэффициентов и помещающие результат во временную переменную, для определённости @1. Генерируется инструкция сдвига, вычисляющая 2n и помещающая результат в другую временную переменную, например @2. Далее в исходной функции выбирается аддитивное целое выражение, результат которого сохраняется в некоторой временной переменной, например, @3, и строится новое выражение @1 + @3 - @2. Это выражение всегда будет равно выражению @3, но содержит зависимость по данным от переменной n.
Некоторые другие тождества, которые могут использоваться аналогичным образом, приведены ниже.
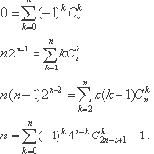
Теоретико-числовые тождества. В качестве примера рассмотрим известную малую теорему Ферма.
ap-1

для любого целого
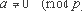
Другие теоретико-числовые тождества, которые также могут использоваться для внесения зависимостей по данным, приведены ниже. Обобщением малой теоремы Ферма является теорема Эйлера:
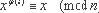
где n и x произвольные целые числа,
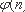
(n-1)!
тогда и только тогда, когда n - простое число.
Использование массивов и динамических структур данных. Динамические структуры данных могут использоваться и для создания искусственных зависимостей по данным. Главный расчёт здесь делается на то, что в настоящее время не существует удовлетворительного алгоритма анализа алиасов, возникающих при использовании указателей и индексов массивов.
В качестве простейшего способа можно предложить размещение всех локальных переменных одного типа в массиве. В тексте функции вместо имени переменной теперь будет использоваться индекс массива. Даже случаев, когда индекс всегда представляет собой литеральную константу, будет достаточно, чтобы поставить в тупик простейшие алгоритмы анализа алиасов, которые рассматривают массив как единое целое.
В момент маскировки программы известно, какие элементы массива заняты существенными, а какие - несущественными переменными. Более того, распределение несущественных переменных по массиву может выбираться произвольным образом. Это может использоваться для построения зависимостей по данным. Пусть f - функция, ставящая в соответствие произвольному целому значению некоторый индекс в массиве, по которому находится несущественная переменная. Тогда искусственные зависимости по данным строятся с помощью выражений вида vars[f(e1)] = e2 или vars[f(e1)] = vars[f(e2)]. Здесь vars - это массив переменных, e1, e2 - выражения, которые включают в себя как существенные, так и несущественные переменные.
Один из простых способов использования динамических структур данных для внесения зависимостей по данным заключается в том, что все значения переменных всех типов хранятся в списке, размещаемом в динамической памяти. Для доступа к переменным вместо их имени используется разыменование специальных указателей. Кроме того, указатели на несущественные переменные время от времени меняют своё положение в списке. В результате окажется, что все обращения к бывшим локальным переменным функции обращаются к объектам в области динамической памяти.Для разделения существенных и несущественных переменных потребуется анализ алиасов в динамической памяти, способный работать с динамическими структурами данных произвольной глубины. В настоящее время не существует такого метода статического анализа алиасов.
Этот подход проиллюстрирован на рис. 8, На котором функция содержит четыре переменных a, b, c и d. Пусть, для определённости, переменные a и b - существенные, а c и d - несущественные. В замаскированной функции вместо этих локальных переменных вводятся переменные p1 и p2, указывающие на звенья списка, размещённого в динамической памяти. Переменная a доступна как p1->prev или как p2->next, а переменная c - как p1->next или как p2->prev.
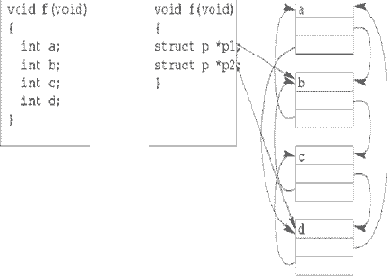
Рис. 8. Использование списков для внесения зависимостей по данным
